2024

VLUE: A New Benchmark and Multi-task Knowledge Transfer Learning for Vietnamese Natural Language Understanding
Phong Nguyen-Thuan Do, Son Quoc Tran, Phu Gia Hoang, Kiet Van Nguyen, Ngan Luu-Thuy Nguyen
Findings of North American Chapter of the Association for Computational Linguistics (NAACL) 2024
We introduce VLUE, the first standardized Vietnamese NLU benchmark spanning five tasks and evaluate seven SOTA models on it. Our model CafeBERT, a Vietnamese-adapted version of XLM-R, sets a new state-of-the-art across all VLUE tasks and is released for public research use.
VLUE: A New Benchmark and Multi-task Knowledge Transfer Learning for Vietnamese Natural Language Understanding
Phong Nguyen-Thuan Do, Son Quoc Tran, Phu Gia Hoang, Kiet Van Nguyen, Ngan Luu-Thuy Nguyen
Findings of North American Chapter of the Association for Computational Linguistics (NAACL) 2024
We introduce VLUE, the first standardized Vietnamese NLU benchmark spanning five tasks and evaluate seven SOTA models on it. Our model CafeBERT, a Vietnamese-adapted version of XLM-R, sets a new state-of-the-art across all VLUE tasks and is released for public research use.
2023

ViHOS: Hate Speech Spans Detection for Vietnamese
Phu Gia Hoang, Canh Duc Luu, Kiet Van Nguyen, Ngan Luu-Thuy Nguyen
European Chapter of the Association for Computational Linguistics (EACL) 2023
Proposed a novel task for Vietnamese NLP, ViHOS - Vietnamese Hate and Offensive Spans, which consists of 12k online comments with advanced annotations on what make a sentence offensive and benchmark experiments.
ViHOS: Hate Speech Spans Detection for Vietnamese
Phu Gia Hoang, Canh Duc Luu, Kiet Van Nguyen, Ngan Luu-Thuy Nguyen
European Chapter of the Association for Computational Linguistics (EACL) 2023
Proposed a novel task for Vietnamese NLP, ViHOS - Vietnamese Hate and Offensive Spans, which consists of 12k online comments with advanced annotations on what make a sentence offensive and benchmark experiments.
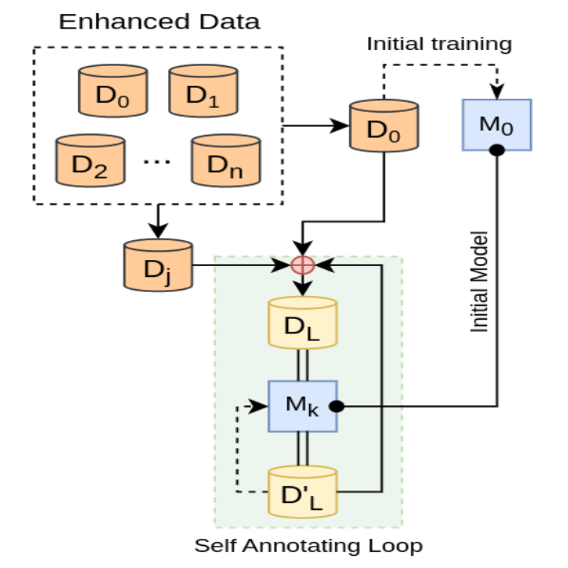
VBD_NLP at SemEval-2023 Task 2: Named Entity Recognition Systems Enhanced by BabelNet and Wikipediae
Phu Gia Hoang, Le Thanh, Hai-Long Trieu
International Workshop on Semantic Evaluation (SemEval) 2023
We enhanced fine-grained NER performance for English and Bangla in SemEval-2023 by augmenting limited training data using BabelNet and Wikipedia redirections, and training mDeBERTa models on this enriched data. Our approach significantly outperformed baseline systems, achieving notable macro-F1 improvements in both languages.
VBD_NLP at SemEval-2023 Task 2: Named Entity Recognition Systems Enhanced by BabelNet and Wikipediae
Phu Gia Hoang, Le Thanh, Hai-Long Trieu
International Workshop on Semantic Evaluation (SemEval) 2023
We enhanced fine-grained NER performance for English and Bangla in SemEval-2023 by augmenting limited training data using BabelNet and Wikipedia redirections, and training mDeBERTa models on this enriched data. Our approach significantly outperformed baseline systems, achieving notable macro-F1 improvements in both languages.
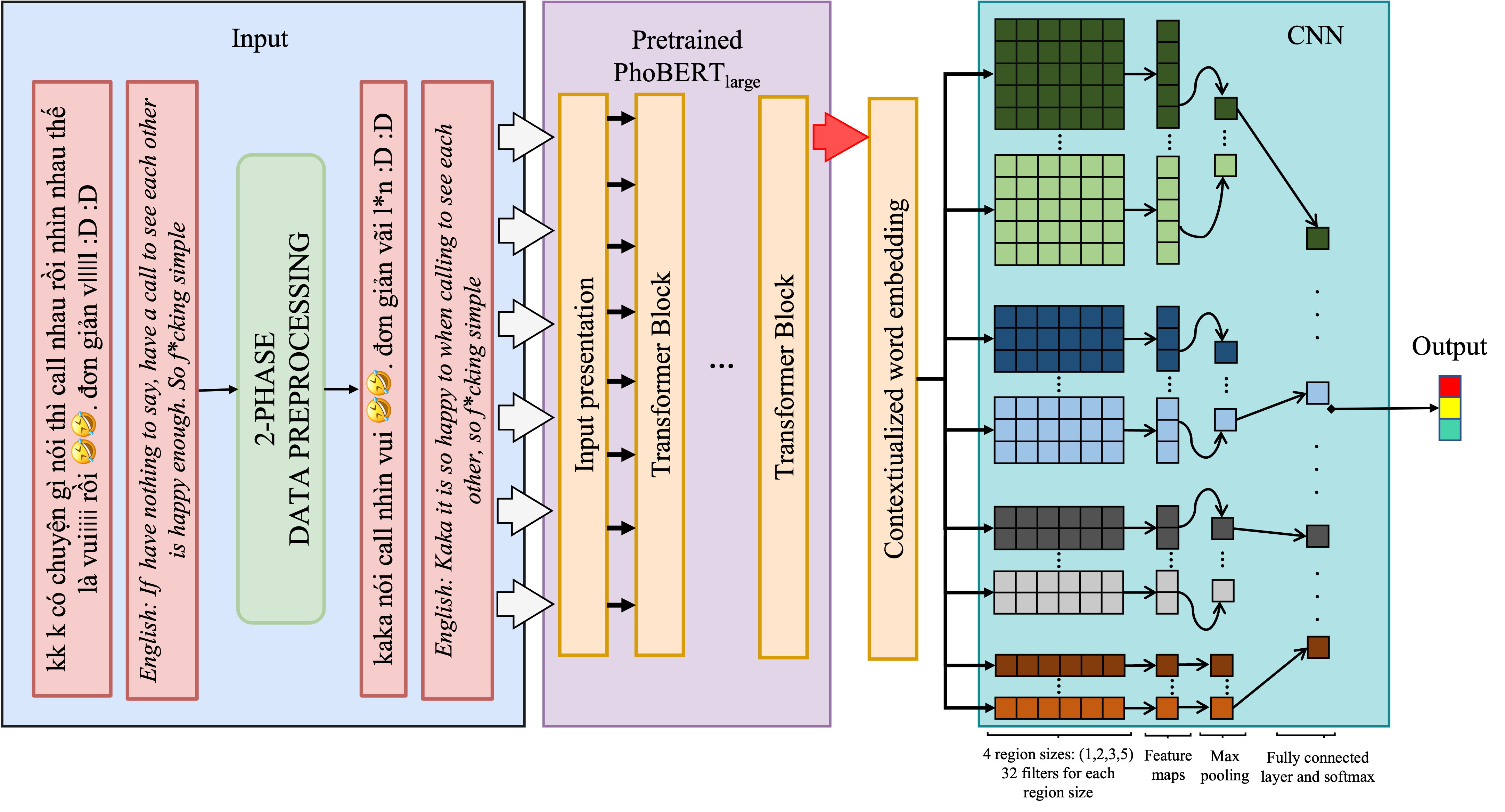
Vietnamese hate and offensive detection using PhoBERT-CNN and social media streaming data
Khanh Quoc Tran, An Trong Nguyen, Phu Gia Hoang, Canh Duc Luu, Trong-Hop Do, Kiet Van Nguyen
Neural Computing and Applications Journal 2023
An end-to-end Vietnamese hate speech detection system combining PhoBERT with Text-CNN, enhanced by tailored preprocessing and data augmentation. Our model achieves state-of-the-art results on benchmark datasets and is deployed in a real-time streaming application, demonstrating both high performance and practical utility.
Vietnamese hate and offensive detection using PhoBERT-CNN and social media streaming data
Khanh Quoc Tran, An Trong Nguyen, Phu Gia Hoang, Canh Duc Luu, Trong-Hop Do, Kiet Van Nguyen
Neural Computing and Applications Journal 2023
An end-to-end Vietnamese hate speech detection system combining PhoBERT with Text-CNN, enhanced by tailored preprocessing and data augmentation. Our model achieves state-of-the-art results on benchmark datasets and is deployed in a real-time streaming application, demonstrating both high performance and practical utility.
2021
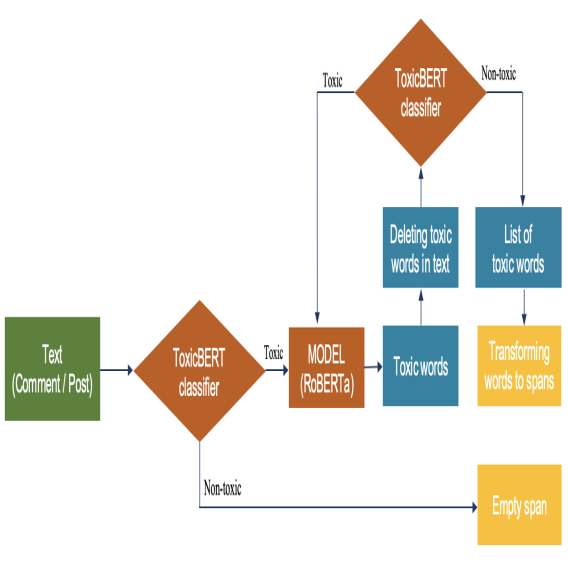
UIT-E10dot3 at SemEval-2021 Task 5: Toxic Spans Detection with Named Entity Recognition and Question-Answering Approaches
Phu Gia Hoang, Luan Thanh Nguyen, Kiet Nguyen
International Workshop on Semantic Evaluation (SemEval) 2021
To tackle toxic language detection in SemEval-2021 Task 5, we explored both NER and QA-based approaches. Our spaCy-based NER model achieved the best F1-score of 66.99% in identifying toxic spans from text.
UIT-E10dot3 at SemEval-2021 Task 5: Toxic Spans Detection with Named Entity Recognition and Question-Answering Approaches
Phu Gia Hoang, Luan Thanh Nguyen, Kiet Nguyen
International Workshop on Semantic Evaluation (SemEval) 2021
To tackle toxic language detection in SemEval-2021 Task 5, we explored both NER and QA-based approaches. Our spaCy-based NER model achieved the best F1-score of 66.99% in identifying toxic spans from text.